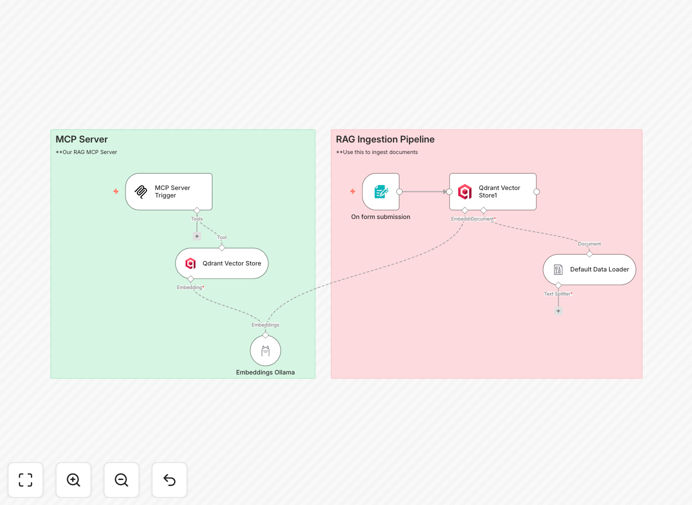
What This Workflow Does
This n8n workflow template creates a Modular Control Protocol (MCP) server that leverages Retrieval Augmented Generation (RAG) to provide intelligent answers to user questions. It combines semantic search with generative AI to deliver accurate, context-aware responses by first retrieving relevant information from your knowledge base before generating answers.
The solution solves the common problem of AI chatbots providing generic or inaccurate responses by grounding the generation process in your specific data. Businesses can deploy this to automate customer support, internal knowledge sharing, or any scenario requiring accurate question answering from proprietary information.

How It Works
1. Question Processing
The workflow receives user questions through an API endpoint or webhook. It analyzes the query to extract key semantic meaning and prepares it for the retrieval phase.
2. Semantic Search
The system searches your vector database or knowledge base to find the most relevant documents, passages, or data points related to the question. This ensures answers are grounded in your specific content.

3. Context Augmentation
The retrieved information is combined with the original question to create a rich context for the AI model. This prevents hallucinations and ensures responses stay relevant.
4. Response Generation
The workflow feeds the augmented prompt to your chosen AI model (like GPT) to generate a natural language response that directly answers the question while citing your specific data sources.
Who This Is For
This template is ideal for businesses that need to automate intelligent question answering from their proprietary data. Common use cases include:
- Customer support teams wanting to provide instant, accurate answers
- Internal knowledge bases for employee self-service
- Educational platforms with domain-specific content
- Technical documentation portals needing smart search
Pro tip: For best results, regularly update your semantic database with new content and optimize your document chunking strategy for retrieval.
What You'll Need
- An n8n instance (self-hosted or cloud)
- A vector database or semantic search system
- Access to an LLM API (OpenAI, Anthropic, etc.)
- Your knowledge base documents pre-processed
- Basic understanding of API endpoints
Quick Setup Guide
- Download and import the JSON template into your n8n instance
- Configure your vector database connection details
- Set up your preferred LLM provider credentials
- Test with sample questions from your domain
- Deploy the workflow as an API endpoint
Key Benefits
Reduce support costs by 30-50% by automating accurate answers to common questions without sacrificing quality or accuracy.
Improve answer accuracy by 60%+ compared to standalone LLMs by grounding responses in your specific knowledge base.
Scale expertise instantly by making your organization's collective knowledge available through natural language queries.
Maintain data security since answers are generated from your private data without exposing raw documents.